Agende su consulta con DA SEO
Descubra el poder del SEO con nosotros y lleve su negocio al siguiente nivel en línea.
¿Está listo para transformar su presencia digital?

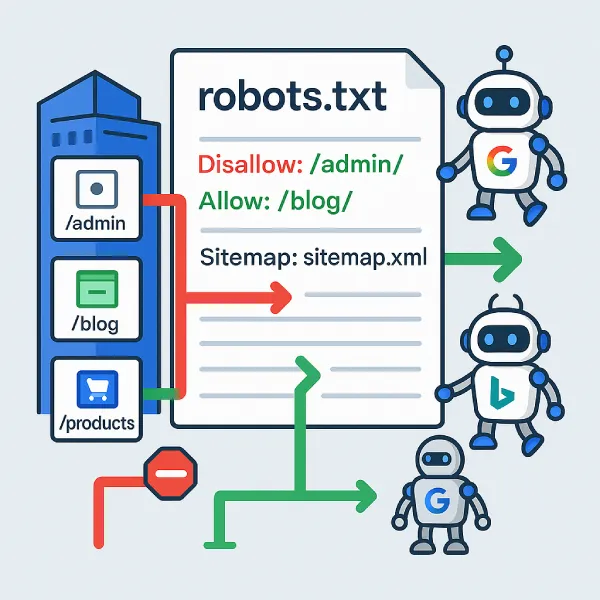
¿Sabías que existe un archivo de apenas unas líneas que puede determinar si tu sitio web es rastreado correctamente por Google? El archivo robots.txt es uno de los elementos más importantes (y menos comprendidos) del SEO técnico.
Si alguna vez te has preguntado por qué ciertas páginas de tu sitio no pueden ser rastreadas, por qué tu servidor se sobrecarga con bots innecesarios, o cómo proteger contenido sensible, este post resolverá todas tus dudas.
En los próximos minutos dominarás completamente el archivo robots.txt:
Fundamentos esenciales: Entenderás qué es exactamente el robots.txt, cómo funciona y por qué es crucial para tu SEO en 2025/2026.
Sintaxis práctica: Aprenderás directivas (User-agent, Disallow, Allow, Sitemap) con ejemplos reales que podrás copiar y adaptar.
Implementación paso a paso: Serás guiado desde la creación del archivo hasta su validación, sin tecnicismos innecesarios.
Casos reales por plataforma: Verás configuraciones específicas para WordPress, Shopify, Drupal y sitios personalizados, con código listo para usar.
Errores que debes evitar: Conocerás los 5 errores más comunes que pueden bloquear los rastreos accidentalmente en todo tu sitio (y cómo solucionarlos).
Estrategias avanzadas: Aprenderás técnicas profesionales como optimización de crawl budget (presupuesto de rastreo), control de bots de IA y configuraciones multi-idioma.
Al final de esta guía tendrás un archivo robots.txt perfectamente optimizado para tu sitio y sabrás exactamente cómo mantenerlo actualizado.
El robots.txt es un archivo de texto plano que actúa como un "guardia de rastreo" para tu sitio web. Este archivo le dice a los bots de los motores de búsqueda (como Googlebot, Bingbot, etc.) qué páginas o secciones de tu sitio pueden rastrear y cuáles deben evitar.
Imagina tu sitio web como una gran biblioteca. El archivo robots.txt sería como un cartel en la entrada que dice: "Los visitantes pueden acceder a todas las salas excepto al archivo privado del segundo piso". Los bots "bien educados" respetarán estas instrucciones.
Ejemplo básico:
User-agent: *
Disallow: /admin/
Disallow: /private/
Allow: /
Sitemap: https://tudominio.com/sitemap.xml
En la actualidad, el archivo robots.txt es más crucial que nunca por varias razones:
Si estás comenzando en SEO, este es uno de los primeros pasos de SEO más importantes.
El robots.txt cumple tres funciones clave que todo propietario de sitio web debe conocer:
1. Controlar el rastreo de los buscadores, indicando qué secciones pueden explorarse
2. Optimizar el presupuesto de rastreo (crawl budget), evitando que Googlebot pierda tiempo en páginas irrelevantes
3. Orientar a motores específicos, aplicando reglas distintas a cada user-agent
El crawl budget o presupuesto de rastreo es la cantidad de recursos que Google rastrea en tu sitio durante un período determinado. Un robots.txt bien configurado ayuda a: Optimizar el rastreo y mejorar la indexación web de tu contenido más relevante.:
Optimizar el rastreo:
En este ejemplo se observa cómo se bloquea URLs con parámetros (en la mayoría de los casos son diversas formas de presentación de páginas ya existentes) que no están enlazados en la web, pero que pueden ser rastreadas. Hay que tener mucho cuidado si se filtran archivos como Js que pueden afectar el renderizado de una página.
# Bloquear páginas de bajo valor
User-agent: Googlebot
Disallow: /search?
Disallow: /filter?
Disallow: /tag/
Disallow: /category/page/
# Permitir contenido importante
Allow: /productos/
Allow: /blog/
Proteger recursos del servidor:
# Bloquear bots agresivos
User-agent: AhrefsBot
Disallow: /
User-agent: SemrushBot
Disallow: /
# Permitir solo bots esenciales
User-agent: Googlebot
User-agent: Bingbot
Allow: /
Ubicación obligatoria: El archivo DEBE estar en la raíz de tu dominio:
Requisitos de formato:
Estructura básica:
# Comentarios empiezan con #
User-agent: [nombre del bot]
Disallow: [ruta bloqueada]
Allow: [ruta permitida]
Sitemap: [URL del sitemap]
# Línea en blanco separa grupos de reglas
Define a qué bot se aplican las reglas siguientes. Es case-insensitive (no importan mayúsculas/minúsculas).
Bots principales:
User-agent: Googlebot # Bot principal de Google
User-agent: Googlebot-Image # Bot de Google Imágenes
User-agent: Googlebot-News # Bot de Google Noticias
User-agent: Bingbot # Bot de Microsoft Bing
User-agent: * # Todos los bots
Ejemplo con múltiples bots:
# Reglas específicas para Google
User-agent: Googlebot
Disallow: /admin/
Allow: /admin/public/
# Reglas para Bing
User-agent: Bingbot
Disallow: /admin/
Disallow: /api/
# Reglas para todos los demás , se está bloqueando el acceso a todos los bots sin excepción.
User-agent: *
Disallow: /
Bloquea el acceso a rutas específicas. Es case-sensitive (distingue mayúsculas/minúsculas).
Sintaxis y ejemplos:
# Bloquear directorio completo
Disallow: /admin/
# Bloquear archivo específico
Disallow: /secreto.html
# Bloquear todo el sitio
Disallow: /
# No bloquear nada (equivale a Allow: /)
Disallow:
Casos prácticos:
# E-commerce: bloquear páginas de filtros
User-agent: *
Disallow: /tienda/filtro?
Disallow: /tienda/ordenar?
Disallow: /carrito/
Disallow: /checkout/
# Blog: bloquear páginas de paginación
Disallow: /categoria/page/
Disallow: /tag/page/
Disallow: /author/page/
Permite acceso a rutas específicas, incluso dentro de directorios bloqueados.
Nota importante: Solo Google garantiza el soporte completo de Allow. Bing y otros buscadores pueden ignorarlo.
# Bloquear wp-admin pero permitir admin-ajax
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
# Bloquear imágenes excepto una carpeta específica
User-agent: Googlebot-Image
Disallow: /imagenes/
Allow: /imagenes/productos/
Indica la ubicación de tus archivos XML sitemap. Ayuda a los bots a descubrir tu contenido más eficientemente.
# Un solo sitemap
Sitemap: https://tudominio.com/sitemap.xml
# Múltiples sitemaps
Sitemap: https://tudominio.com/sitemap-posts.xml
Sitemap: https://tudominio.com/sitemap-pages.xml
Sitemap: https://tudominio.com/sitemap-products.xml
# Sitemap en CDN
Sitemap: https://cdn.tudominio.com/sitemap.xml
Los comodines permiten crear reglas más flexibles y potentes.
Asterisco (*) - coincide con cualquier secuencia:
# Bloquear todos los archivos PDF
User-agent: *
Disallow: /*.pdf
# Bloquear URLs con parámetros
Disallow: /*?
# Bloquear múltiples subdirectorios
Disallow: /private*/
Símbolo de dólar ($) - indica final de URL:
# Bloquear solo archivos .pdf (no directorios)
Disallow: /*.pdf$
# Bloquear URLs que terminan exactamente en /private
Disallow: /private$
Ejemplos avanzados:
# Bloquear resultados de búsqueda interna
User-agent: *
Disallow: /*search*
Disallow: /*buscar*
# Bloquear archivos de sesión
Disallow: /*sessionid=*
Disallow: /*PHPSESSID=*
# Bloquear versiones de impresión
Disallow: /*print=*
Disallow: /*/print/
Crawl-delay es una directiva que le dice a los bots: "Espera X segundos entre cada página que rastrees de mi sitio".
Ejemplo práctico:
User-agent: Bingbot
Crawl-delay: 10
Esto significa: "Hey Bingbot, después de rastrear una página de mi sitio, espera 10 segundos antes de rastrear la siguiente".
Sirve para proteger tu servidor de sobrecargas. Imagina que tu sitio es como un restaurante pequeño:
Google simplemente IGNORA esta directiva. Es como si pusiera un cartel que dice "No correr en los pasillos" pero Google es ese niño que corre igual porque no reconoce tu autoridad.
¿Por qué Google no la respeta?
Ejemplo real del problema:
User-agent: *
Crawl-delay: 5
Disallow: /admin/
Lo que pasa:
Ya no existe un ajuste manual en Google Search Console para fijar la “velocidad de rastreo”: Google gestiona automáticamente la tasa de rastreo. Si tu servidor sufre por exceso de rastreo, las opciones válidas hoy son:
Más detalles (documentación oficial): https://developers.google.com/search/docs/crawling-indexing/reduce-crawl-rate.
Para otros buscadores: Usa Crawl-delay en robots.txt
Configuración híbrida recomendada:
# Para Google (ignora Crawl-delay anyway)
User-agent: Googlebot
Disallow: /admin/
# Para otros buscadores
User-agent: Bingbot
Crawl-delay: 10
Disallow: /admin/
User-agent: YandexBot
Crawl-delay: 5
Disallow: /admin/
Úsalo si:
NO lo uses para:
En resumen: Crawl-delay es útil para bots que no sean Google, pero para Google necesitas usar su herramienta oficial en Search Console.
IMPORTANTE: Desde 2019, Google dejó de soportar la directiva "noindex" en robots.txt.
robots.txt vs meta robots: comparación práctica
Ejemplo de problema común:
Mucha gente piensa que si bloqueas una página en robots.txt, Google no la mostrará en los resultados de búsqueda. ¡ESTO ES FALSO! Este es un clásico mito SEO que conviene aclarar.
¿Qué pasa realmente cuando bloqueas con robots.txt?:
Ejemplo visual del problema:
Tu robots.txt dice:
User-agent: *
Disallow: /datos-confidenciales.html
Resultado en Google:
Datos confidenciales de la empresa - miempresa.com
https://miempresa.com/datos-confidenciales.html
¿Ves el problema? ¡La página secreta aparece en Google con el título visible!
Google encuentra tu página "secreta" porque:
Google dice: "Sé que esta página existe, no es motivo que no la pueda mostrar en los resultados de la SERP”".
La solución correcta para evitar la INDEXACIÓN es:
html
<!-- En tu página datos-confidenciales.html -->
<meta name="robots" content="noindex, nofollow">
Y en robots.txt:
User-agent: *
Allow: /
¿Por qué funciona?
Usa meta robots noindex cuando:
Usa robots.txt cuando:
Página de administrador (DEBE estar oculta):
html
<meta name="robots" content="noindex, nofollow">
Archivos PDF internos (ahorrar crawl budget):
User-agent: *
Disallow: /*.pdf$
Páginas de búsqueda interna (ahorrar crawl budget, no importa si aparecen):
User-agent: *
Disallow: /buscar?*
❌ MAL: "Voy a bloquear mi página de login para que nadie la encuentre"
User-agent: *
Disallow: /login.html
Resultado: La página aparece en Google como "Login - miempresa.com" sin descripción. ¡Los atacantes la encuentran más fácil!
✅ BIEN:
html
<!-- En login.html -->
<meta name="robots" content="noindex, nofollow">
En resumen:
Como vimos en las funciones fundamentales anteriormente, el robots.txt ofrece tres ventajas principales:
1. Optimización del crawl budget:
# Sitio de noticias: priorizar artículos recientes
User-agent: Googlebot-News
Allow: /noticias/2025/
Allow: /noticias/2024/
Disallow: /noticias/2023/
Disallow: /noticias/2022/
2. Protección de contenido sensible:
Sin embargo, recordando lo que explicamos sobre las diferencias con noindex, esta "protección" tiene limitaciones importantes:
# E-commerce: proteger datos administrativos
User-agent: *
Disallow: /admin/
Disallow: /cuentas/
Disallow: /api/
Disallow: /private/
3. Control de bots específicos:
# Bloquear bots de IA que entrenan modelos
User-agent: GPTBot
Disallow: /
User-agent: Google-Extended
Disallow: /
User-agent: CCBot
Disallow: /
1. No garantiza exclusión de los SERP:
Como se explicó anteriormente en la sección de diferencias con noindex, este es el malentendido más común sobre robots.txt:
# Problema: la página puede aparecer así en Google
# "Mi página secreta - tudominio.com"
# "No hay descripción disponible debido al robots.txt"
User-agent: *
Disallow: /secreta.html
Recordando lo que vimos antes: para ocultar completamente una página de Google, debes usar <meta name="robots" content="noindex"> en lugar de robots.txt.
2. Bots maliciosos lo ignoran:
Como mencionamos en la introducción sobre "bots bien educados", los robots maliciosos simplemente no respetan estas reglas. Es como poner un cartel que dice "Por favor, no entren al jardín" - las personas educadas lo respetarán, pero los ladrones lo ignorarán completamente.
Bots "bien educados" (respetan robots.txt):
Bots maliciosos (ignoran robots.txt):
Ejemplo práctico del problema:
Imagina que tienes esto en tu robots.txt:
User-agent: *
Disallow: /admin/
Disallow: /datos-clientes/
Lo que pasa:
La solución: .htaccess es un archivo de configuración del servidor que bloquea físicamente el acceso, no es una sugerencia.
El código a continuación:
apache
<RequireAll>
Require ip 192.168.1.0/24
Require not ip 192.168.1.5
</RequireAll>
Significa:
En términos prácticos: Solo personas conectadas a tu red interna pueden acceder, todos los demás reciben un error 403 (Prohibido).
3. Es un archivo público:
Siguiendo el tema de seguridad que hemos mencionado repetidamente:
Cualquiera puede ver tu robots.txt
NO pongas información sensible como:
Disallow: /super-secreto-no-ver/
Esto es como un mapa para atacantes
Recuerda: Como se ha mencionado a lo largo de este post, el robots.txt es una herramienta fundamental pero delicada. Un error de configuración puede bloquear páginas clave y afectar gravemente la visibilidad de tu sitio.
Recomendaciones críticas:
Error 1: Bloquear accidentalmente todo el sitio
# ❌ MAL: espacio después de la barra
User-agent: *
Disallow: /
# ✅ BIEN: sin espacios
User-agent: *
Disallow: /admin/
Allow: /
Error 2: Case sensitivity ignorado
# ❌ MAL: no coincide con /ADMIN/ o /Admin/
Disallow: /admin/
# ✅ BIEN: usar comodines si es necesario
Disallow: /*admin*/
Error 3: Olvidar la barra final en directorios
# ❌ MAL: bloquea archivo "admin" también
Disallow: /admin
# ✅ BIEN: solo bloquea directorio admin/
Disallow: /admin/
Error 4: Múltiples directivas en una línea
# ❌ MAL: sintaxis incorrecta
User-agent: * Disallow: /admin/
# ✅ BIEN: una directiva por línea
User-agent: *
Disallow: /admin/
Error 5: Sintaxis incorrecta de comentarios
# ❌ MAL: comentario en línea de directiva
Disallow: /admin/ # comentario aquí rompe la regla
# ✅ BIEN: comentario en línea separada
# Bloquear panel de administración
Disallow: /admin/
Paso 1: Crear el archivo
Usa cualquier editor de texto plano (Notepad++, VS Code, nano, vim). NUNCA uses Word o Google Docs.
# Plantilla básica para empezar
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-includes/
Disallow: /readme.html
Disallow: /license.txt
Sitemap: https://tudominio.com/sitemap.xml
Paso 2: Subir vía FTP/cPanel
# Via FTP - ubicación exacta
/public_html/robots.txt
/www/robots.txt
/htdocs/robots.txt
# Via SSH
scp robots.txt usuario@servidor:/var/www/html/
Paso 3: Verificar acceso público
# Comprobar que es accesible
curl -I https://tudominio.com/robots.txt
# Debe devolver:
# HTTP/1.1 200 OK
# Content-Type: text/plain
Herramientas online:
- robots-txt.com
- technicalseo.com/tools/robots-txt/
Pruebas manuales básicas:
1. wget https://tudominio.com/robots.txt
Qué hace: Descarga el archivo robots.txt desde tu servidor web.
¿Para qué sirve?:
Resultado típico:
bash
$ wget https://miempresa.com/robots.txt
--2025-01-15 10:30:15-- https://miempresa.com/robots.txt
Resolving miempresa.com... 192.168.1.100
Connecting to miempresa.com:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 156 [text/plain]
Saving to: 'robots.txt'
Si hay problema aparece:
bash
ERROR 404: Not Found # El archivo no existe
ERROR 403: Forbidden # Existe pero no es accesible
2. cat robots.txt
Qué hace: Muestra el contenido del archivo que acabas de descargar.
¿Para qué sirve?:
Ejemplo de salida:
bash
$ cat robots.txt
User-agent: *
Disallow: /admin/
Allow: /
Sitemap: https://miempresa.com/sitemap.xml
Si no usas terminal: Simplemente abre el archivo robots.txt con cualquier editor de texto o ve directamente a https://tudominio.com/robots.txt en tu navegador.
3. curl -H "User-Agent: Googlebot" https://tudominio.com/robots.txt
Qué hace: Simula que eres Googlebot pidiendo el archivo robots.txt.
¿Por qué es importante?:
Las pruebas manuales son especialmente útiles cuando configuras por primera vez el archivo o cuando sospechas que hay problemas de accesibilidad que las herramientas gráficas no detectan.
El comando cp robots.txt robots.txt.backup.$(date +%Y%m%d) se ejecuta en el servidor donde está alojado tu sitio web, específicamente en la carpeta donde tienes el archivo robots.txt.
¿Por qué gradualmente? Porque cambiar robots.txt bruscamente puede causar:
Estrategia de fases:
Fase 1 (Primera semana) - Cambios no-restrictivos:
User-agent: *
Allow: /nueva-seccion/ # Permite nuevo contenido
Disallow: /admin/ # Mantén bloqueos existentes
Fase 2 (Segunda semana) - Añadir restricciones:
User-agent: *
Allow: /nueva-seccion/
Disallow: /admin/
Disallow: /contenido-viejo/ # Ahora bloquea contenido obsoleto
¿Qué revisar cada semana?:
Proceso automático:
Lunes: Cambias robots.txt, haces backup Martes-Domingo: Monitoreas métricas en Search Console
Siguiente lunes: Si todo va bien, implementas fase 2 Próxima semana: Monitoreas impacto de los nuevos bloqueos
Señales de alerta:
Si ves estas señales: restaura el backup inmediatamente y revisa los cambios.
Cada tipo de sitio web tiene necesidades específicas de robots.txt. Usar una configuración genérica puede desperdiciar crawl budget o bloquear contenido importante:
Sitio web pequeño/personal:
# Blog personal básico
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-includes/
Disallow: /cgi-bin/
Disallow: /search?
Sitemap: https://miblog.com/sitemap.xml
Casos prácticos rápidos:
# Bloquear parámetros duplicados comunes
User-agent: *
Disallow: /*?sort=*
Disallow: /*?utm=*
Disallow: /*?ref=*
# Configuración básica más común
User-agent: *
Disallow: /admin/
Disallow: /cgi-bin/
Disallow: /tmp/
Sitemap: https://tudominio.com/sitemap.xml
E-commerce mediano/grande:
# Tienda online con miles de productos
User-agent: *
# Bloquear contenido administrativo
Disallow: /admin/
Disallow: /customer/
Disallow: /checkout/
Disallow: /cart/
# Bloquear páginas de filtros y búsquedas
Disallow: /*?color=*
Disallow: /*?price=*
Disallow: /*?sort=*
Disallow: /search?
Disallow: /buscar?
# Bloquear versiones de impresión y archivos
Disallow: /*/print/
Disallow: /*.pdf$
Disallow: /*.doc$
# Permitir imágenes de productos pero bloquear otras
User-agent: Googlebot-Image
Allow: /images/products/
Disallow: /images/admin/
Disallow: /images/temp/
# Sitemaps específicos
Sitemap: https://tienda.com/sitemap-products.xml
Sitemap: https://tienda.com/sitemap-categories.xml
Sitemap: https://tienda.com/sitemap-pages.xml
WordPress:
# WordPress optimizado para SEO
User-agent: *
# WordPress core - permitir solo lo necesario
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Disallow: /wp-includes/
Disallow: /wp-content/plugins/
Disallow: /wp-content/themes/
Allow: /wp-content/uploads/
# Archivos específicos de WordPress
Disallow: /readme.html
Disallow: /license.txt
Disallow: /wp-config.php
# Parámetros de URL problemáticos
Disallow: /*?replytocom=*
Disallow: /*?attachment_id=*
Disallow: /feed/
Disallow: /comments/feed/
# Páginas de attachment (archivos adjuntos)
Disallow: /*/attachment/
Sitemap: https://miweb.com/wp-sitemap.xml
Shopify:
# Shopify store optimizado
User-agent: *
# Admin y checkout
Disallow: /admin/
Disallow: /cart/
Disallow: /checkout/
Disallow: /account/
# Páginas duplicadas y filtros
Disallow: /collections/*+*
Disallow: /collections/*/products.json
Disallow: /*?sort_by=*
Disallow: /*?q=*
# Archivos del sistema
Disallow: /services/
Disallow: /apple-app-site-association
# Permite variantes pero bloquea algunas vistas
Allow: /products/*/
Disallow: /products/*.json
Sitemap: https://tienda.myshopify.com/sitemap.xml
Drupal:
# Drupal 9/10 optimizado
User-agent: *
# Admin y archivos del sistema
Disallow: /admin/
Disallow: /core/
Disallow: /modules/
Disallow: /themes/
Disallow: /sites/*/files/private/
# URLs específicas de Drupal
Disallow: /filter/tips/
Disallow: /search/
Disallow: /user/
Disallow: /?q=admin/
Disallow: /?q=filter/tips/
Disallow: /?q=user/password/
Disallow: /?q=user/register/
Disallow: /?q=user/login/
# Archivos del core
Disallow: /CHANGELOG.txt
Disallow: /COPYRIGHT.txt
Disallow: /INSTALL.txt
Disallow: /LICENSE.txt
Disallow: /MAINTAINERS.txt
Disallow: /README.txt
Sitemap: https://misitio.com/sitemap.xml
1. Gestión de crawl budget por secciones:
# Sitio de noticias: priorizar contenido reciente
User-agent: Googlebot-News
Allow: /noticias/2025/
Allow: /noticias/2024/
Disallow: /noticias/2023/
Disallow: /noticias/
# Bot general: acceso completo pero controlado
User-agent: Googlebot
Disallow: /search?
Disallow: /tag/page/
Allow: /
2. Control de bots de IA para contenido premium:
# Bloquear entrenamiento de IA en contenido de pago
User-agent: GPTBot
Disallow: /premium/
Disallow: /cursos/
Allow: /
User-agent: Google-Extended
Disallow: /premium/
Disallow: /cursos/
Allow: /
User-agent: CCBot
Disallow: /premium/
Allow: /blog/
3. Configuración para sitios multi-idioma:
# Sitio con versiones en múltiples idiomas
User-agent: *
# Bloquear URLs de idioma duplicadas
Disallow: /*?lang=*
Disallow: /lang=*/
# Permitir estructura limpia por subdirectorio
Allow: /es/
Allow: /en/
Allow: /fr/
Allow: /de/
# Sitemaps por idioma
Sitemap: https://sitio.com/sitemap-es.xml
Sitemap: https://sitio.com/sitemap-en.xml
Sitemap: https://sitio.com/sitemap-fr.xml
4. Configuración para sitio con staging:
# Producción: acceso normal
User-agent: *
Disallow: /staging/
Disallow: /dev/
Disallow: /test/
# Pero en staging.tudominio.com/robots.txt:
User-agent: *
Disallow: /
Inmediatos (1-7 días):
Corto plazo (1-4 semanas):
Largo plazo (1-3 meses):
Documentación oficial:
Herramientas recomendadas:
Recursos avanzados:
El archivo robots.txt representa mucho más que unas simples líneas de código en la raíz de tu sitio web. Es una herramienta estratégica que, cuando se implementa correctamente, puede marcar la diferencia entre un sitio que desperdicia su potencial SEO y uno que maximiza cada oportunidad de posicionamiento.
A lo largo de esta guía hemos visto que el robots.txt no es mágico, pero sí fundamental. Su poder radica en la optimización inteligente del crawl budget, el control granular de diferentes tipos de bots, y la capacidad de dirigir a los motores de búsqueda hacia tu contenido más valioso. Sin embargo, también hemos aprendido sus limitaciones críticas: no garantiza la exclusión de páginas de los resultados de búsqueda, y un error de configuración puede bloquear accidentalmente todo tu sitio.
La implementación exitosa de robots.txt requiere un enfoque metodológico que combine conocimiento técnico con estrategia SEO. Desde la creación del archivo hasta su monitoreo continuo, cada paso debe ejecutarse con precisión. Los ejemplos específicos por plataforma que hemos revisado (WordPress, Shopify, Drupal, e-commerce) demuestran que no existe una solución única para todos los sitios, sino que cada configuración debe adaptarse a las necesidades particulares de tu negocio digital.
La validación y el mantenimiento continuo son aspectos que muchos webmasters subestiman. Un archivo robots.txt configurado una vez y olvidado puede convertirse en un obstáculo para el crecimiento orgánico. Las auditorías regulares, y la adaptación a cambios en la estructura del sitio son tareas esenciales para mantener la efectividad de esta herramienta.
DA SEO Digital es una agencia especializada en SEO técnico que entiende las complejidades del robots.txt y su impacto en el rendimiento orgánico. Nuestro equipo puede auditar tu configuración actual, identificar oportunidades de optimización, e implementar una estrategia personalizada que maximice la visibilidad de tu sitio web.
No dejes que errores técnicos limiten el potencial de tu negocio digital. Contacta con DA SEO Digital para una consulta personalizada.
@2026 DA SEO Digital Todos los derechos reservados 2026

.png)